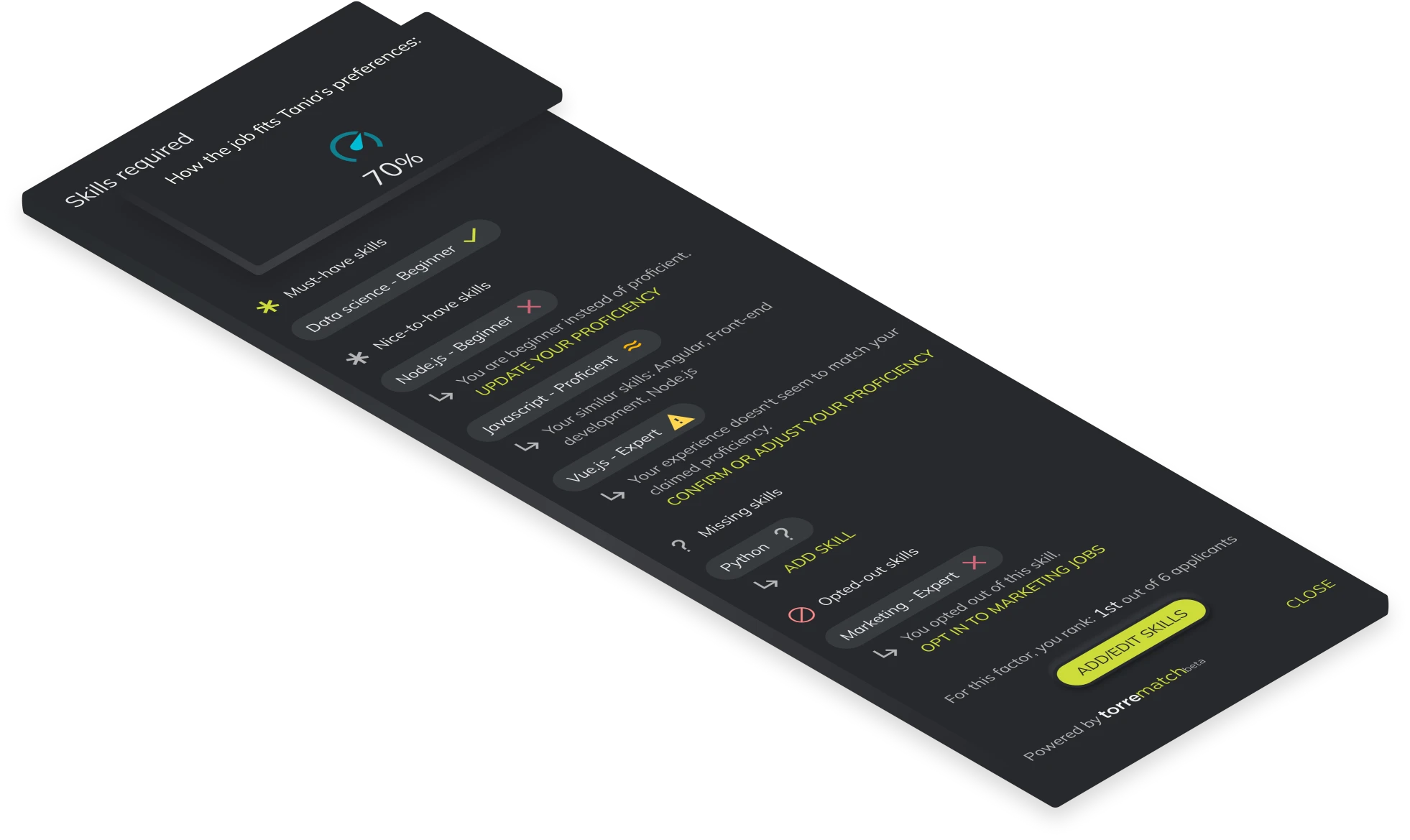
The skill-proficiency feature’s purpose is to validate if a user is able to perform at the required level of the job considering its skills and proficiencies on their profile.
The data for this factor is captured by the candidates themselves. The candidates are able to validate their skills in the onboarding process of the platform, in the edit section while viewing their genomes, through the recruiter bot, while changing experiences or through importing resumes.
Talent seekers can specify their requirements in the job post onboarding or while editing the job.
We validate the data that candidates give us in multiple ways.
Experiences of candidates can have related skills and they can be verified by other existing profiles. The verifications make the skill more likely to be true information.
Candidates can have recommendations for skills with their related proficiencies. This gives the skills and proficiencies more credibility.
3.1.3.3.
Through related experiences
We check the amount of years of experience that a candidate has with all of their skills and we validate the related proficiency with that experience.
3.1.3.4.
Skill-experience relevance
We check for every experience that’s linked to a skill, how relevant that experience actually is for the linked skill.
For each skill the job requires, we assess the corresponding skills in the candidate's genome. This evaluation involves two key aspects: measuring the similarity between the skills and comparing the proficiency levels.
3.1.5.1.
Skill similarity
First, we standardize and map every skill to a normalized version. We then employ a string comparison technique. If the genome's skill and the job's skill are an exact match, we assign a similarity score of 1. If they do not match precisely, we use our skill graph to check for any possible connections between these two skills. In cases where no direct connection exists in the skill graph, we resort to a data science/word2vec model to calculate the similarity score.
3.1.5.2.
Skill experiences
In some cases (unrecommended) the job requires a years of experience requirement instead of a proficiency. In this case, we compare the user’s years of experience with all of the skills with a similarity bigger than 0.
We conduct a comprehensive comparison of each job skill with every skill in the candidate's genome. In this process, we calculate both Skill similarity and proficiency similarity for each pairing and multiply these scores together. The highest resulting value for each job skill is taken as the individual's score for that particular skill.
Finally, to determine the overall job matching score, we aggregate all the maximum scores calculated for each skill and divide the sum by the total number of skills. This gives us the total score on how well a candidate can perform the skill requirements of a given job.
3.1.6.
Mathematical description
The mathematical equation for the entire described process can be expressed as follows:
Let:
The total job matching score is calculated as follows:

Where:
- Similarity_Score(S(j), S(g)) is defined as:
- If exact string match → score = 1
- Else
- If the skills are connected in the skillgraph:
- Multiply the weight of each edge until you reach the job skill node. The result of the multiplication is the weight.
- Else:
- Compute the vector for both skills using word2vec and compare both vectors to calculate the similarity instead.
- Proficiency_Score(S(j), S(g)) is defined as:
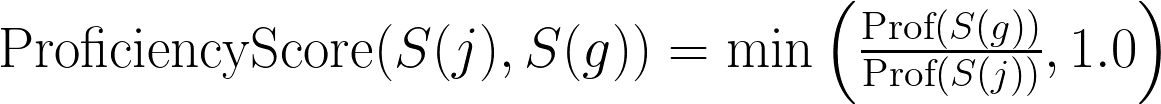
Uncertainty factors of this feature are in “missing skills only”. When a skill is missing from the candidate’s skillset we don’t assume that the person doesn't have it but instead, we let the candidate and talent seeker know that we have some missing information about the user. This is then reflected in the score as an uncertainty range.

