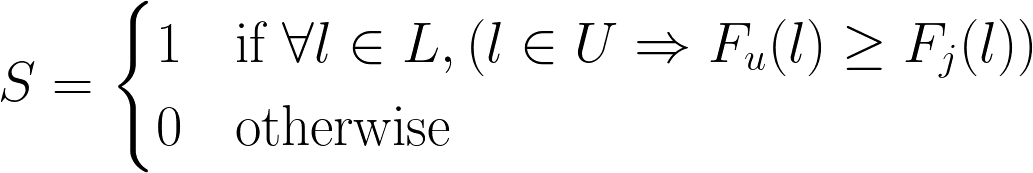3.2. Language fluency validation
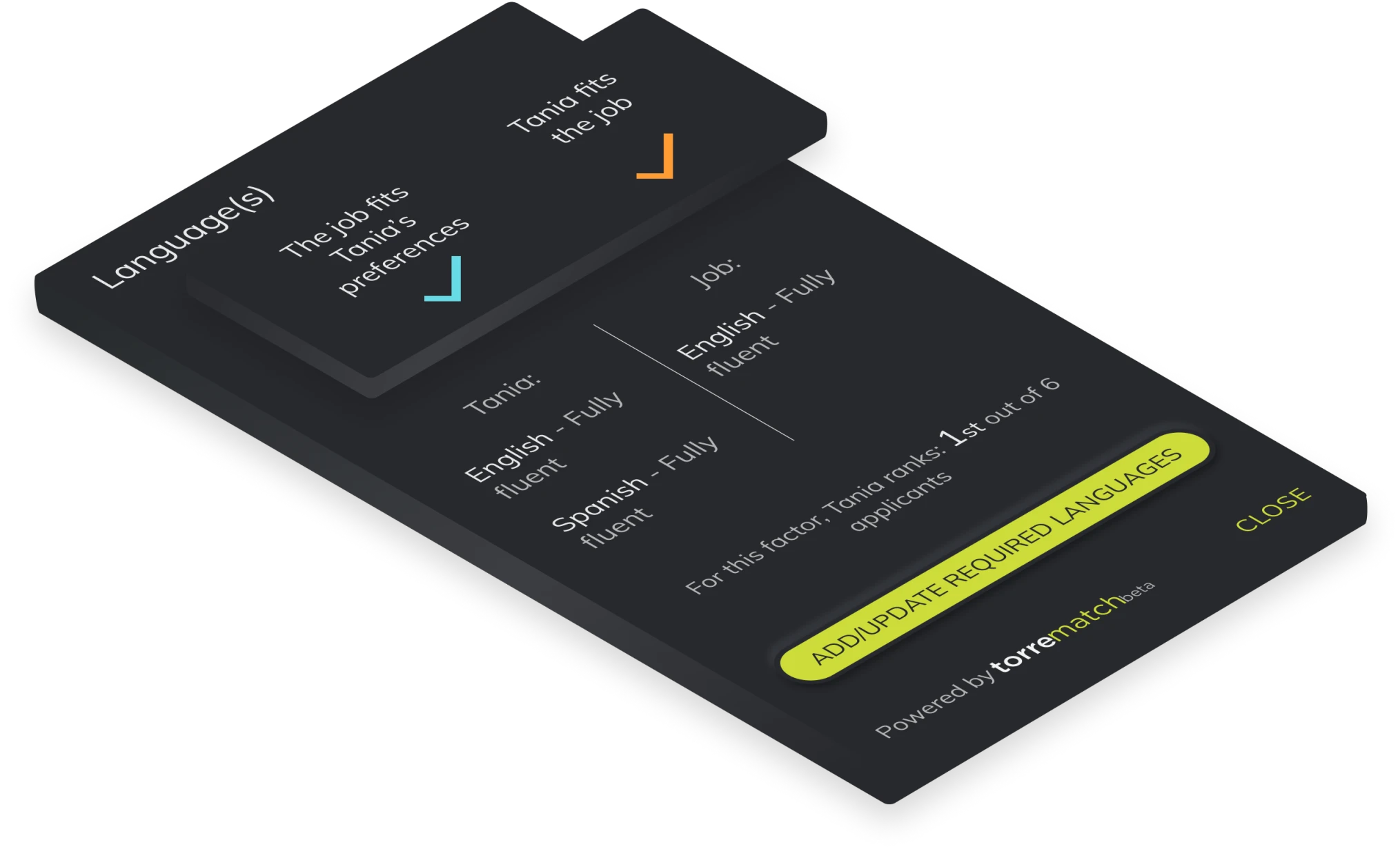
The language-fluency feature's purpose is to validate if a user is able to perform at the required level of the job considering languages and fluencies on their profile.
The data for this factor is captured by the professionals themselves. The professionals are able to validate their languages and fluencies in the onboarding process of the platform, in the edit section while viewing their genomes, through the recruiter bot. Also, we automatically detect languages based on a user's location/IP if they don't provide us with a language themselves.
Talent seekers can specify their requirements in the job post onboarding or while editing the job.
For every language in the job requirements, we check the user's languages and their fluencies. If a user is missing a language or if their fluency is lower than the job requirements, we filter the user from the suggestions and the user will score 0 for this factor.
Uncertainty factors of this feature are in “missing languages only”. When a language is missing from the professional's skillset we don't assume that the person doesn't have it but instead, we let the professional and talent seeker know that we have some missing information about the user. This is then reflected in the score as an uncertainty range.