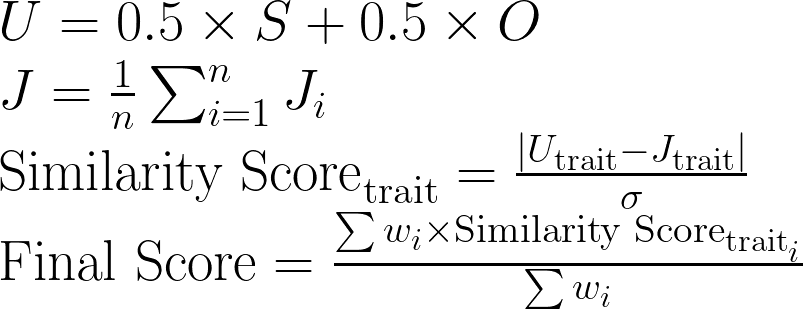4.2. Behavioral similarity

The purpose of this feature is to measure how well the job seeker compares to the job in terms of behavioral traits. This feature combines over 40 different individual factors and combines them into one score.
We gather data from the professionals themselves by having them perform a 40-question test. The professional also requests others to perform the questionnaires for them to validate data and get more insights.
Similar to the professional side we validate questions by having other people fill in reports about the talent seekers. For a job post, we use all traits of all visible members of the job post.
Professional experiences and associated skills can be verified by other profiles, enhancing their credibility.
These are the current traits taken into account for reports:
Torre's behavioral traits questionnaire is a derivative of the Organizational Culture Profile instrument (OCP), developed by Charles A. O'Reilly III, Ph.D., and the HEXACO model, authored by Kibeom Lee, Ph.D., and Michael C. Ashton, Ph.D., as well as Torre's own research on relevant traits. OCP and HEXACO are some of the most scientifically and academically accepted instruments available.
The algorithm creates combined reports of the combination of self and observed reports. The self-report of a user makes up for 50% of their personality representation and all observer reports make up the other 50% of the report. For the job, we take all visible members of a job, compute the behavioral representation as mentioned before, and combine all those representations into one representation for the job.
After this, each individual trait is compared between the job seeker and the job representation. We compare how similar their scores are by taking the difference of the average of the representation of each party. That difference we compare to the standard deviation of our total user base to determine how important that difference is. This results in an individual similarity score for each of the traits. Then we combine those traits by taking the weighted average of all different scores using the importance of the differences mentioned here before.
4.2.6.
Mathematical description
The mathematical formula for this process is as follows:
- U represents the total behavioral trait vector of the professional.
- S represents the self-reported behavioral trait vector.
- O represents the observers-reported behavioral trait vector.
- J represents the Total behavioral trait vector of the job.
- Utrait and Jtrait represent the scores for a particular trait in the user and job representations, respectively.
- wi represents the weight assigned to the difference in the ith trait, based on its importance.
- σ is the standard deviation of trait scores across the user base.